The AICommunityOWL is a private, independent network of AI enthusiasts. It was founded in 2020 by employees of Fraunhofer IOSB-INA, the OWL University of Applied Sciences (TH OWL), the Centrum Industrial IT (CIIT) and Phoenix Contact. Together, we believe in digital progress through the use of machine learning. We want to create sustainable solutions for the challenges of the future: industry, mobility, smart buildings and smart cities – and above all, for people!
The Machine Learning Reading Group (MLRG) of the AICommunityOWL has the goal to get a better understanding of current trends in machine learning on a technical level. The target audience are researchers and practitioners in the field of machine learning. We read and discuss current papers with a high media impact or prominent positioning (at least orals) of the leading conferences, e.g. NeurIPS, ICML, ICLR, AISTATS, UAI, COLT, KDD, AAAI, CVPR, ACL, or IJCAI. Attendees are expected to have read (or skimmed) the papers that are going to be presented so as not to be thrown off by the notation or problem statement and to be able to participate in informed discussions related to the paper. Suggestions for future papers are encouraged, as are volunteer presenters.
We hold our next online meeting on Tuesday, December 14th, at 16:00 under this link.
Don’t miss the date and save the event to your calendar:
Next Session Title:
NoRML: No-Reward Meta Learning
https://arxiv.org/abs/1903.01063
Abstract:
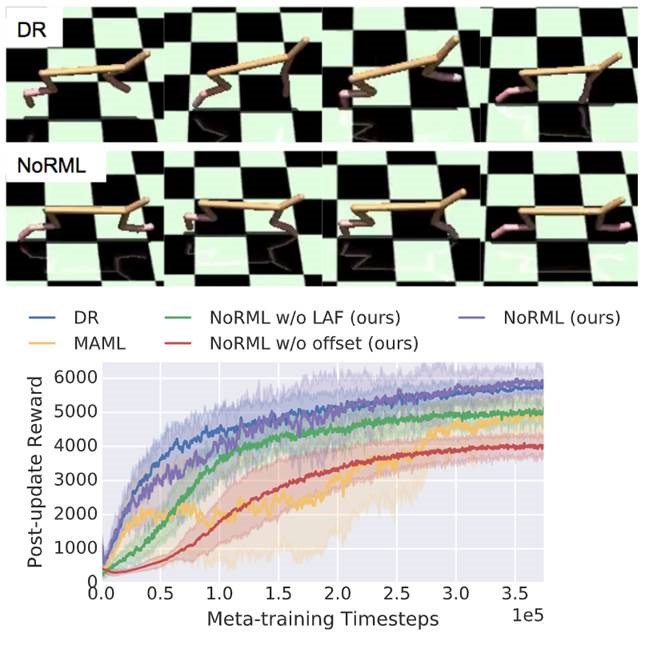
Irregularly sampled time series occur in several domains like medical technology, production monitoring, and It is critical for agents to efficiently adapt to the dynamics of the environment in order to successfully operate in the real world. The Reinforcement Learning (RL) agents typically need external reward feedback in order to adapt to a task with changed dynamics. However, for many real-world tasks, the reward signal might not be readily available. Even if the reward signal is available, the difference between various environments can be only observable from the dynamics and not through the feedback reward signal. The presented paper proposes a new method that enables the self-adaptation of learned policies: No-Reward Meta Learning (NoRML). NoMRL is an extension of Model Agnostic Meta Learning (MAML) that uses observable dynamics of the environment in place of explicit reward function in MAML’s finetune step. This technique has a more expressive update step than MAML, while it still follows a gradient-based approach. For a more targeted exploration, the presented approach implements an extension to MAML that effectively discounts the meta-policy parameters from the fine-tuned policies’ parameters. The NoRML method is studied on several synthetic control problems as well as common benchmark environments. The benchmarking results show that NoRML outperforms the MAML when the environment dynamics change between tasks.
Speakers:
Vishal Rangras (TH OWL and Fraunhofer IOSB-INA)
For questions or suggestions of topics, feel free to contact markus.lange-hegermann@th-owl.de
Signup to the MLRG Mailing List to never miss another session!